Deep Speech is an open-source speech-to-text engine that has been around since November 2017. The models released are trained with Mozilla Common Voice Project so anyone interested can contribute and improve that open dataset. Also if you're into ASR algorithms and implementations you can take a look at this introduction by Reuben Morais or deep dive in Baidu Research by Silicon Valley AI Lab.
In this note, I'll focus on setting up the environment and run Deep Speech on Jetson Nano as I'm looking for the most natural communication interface for my home automation project. Even that I'm not an AI/ML developer, I found it pretty straightforward to make it work.
Let Jetty hear us.
The first dilemma in setting up the environment was choosing the right microphone. For testing, you can use any input, but in real use case, you'll need some far-field microphone. I used ReSpeaker 4 Mic Array , as it implements few useful algorithms for building voice-enabled device.
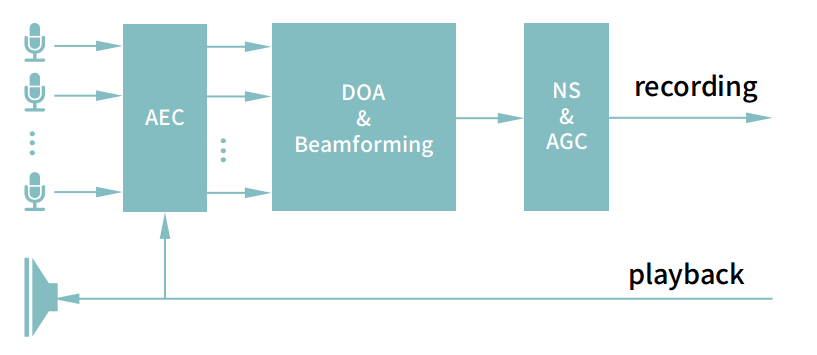
- Acoustic Echo Cancellation (AEC) - it essentially works by “telling” the microphone to ignore any sounds coming out of the loudspeaker using a special input called the “reference”. This keeps the AEC algorithm well informed of any audio processing that ultimately alters the sound of the loudspeakers.
- Direction of Arrival (DOA) and Beamforming - it provides directional signal reception in reverberant and noisy environments.
- Noise suppression (NS) and Automatic Gain Control (AGC) - to handle large dynamic range of signals without losing an information.
After connecting the array with USB interface, it'll be automatically recognized as input/output device on Linux. To update the firmware I'll use python script deliveredy by Respeaker. It's available in two options:
1_channel_firmware.bin with just 1 channel that has processed audio for ASR
6_channels_firmware.bin with 6 channels: channel 0: processed audio for ASR, channel 1-4: 4 microphones' raw data, channel 5: playback
In my case I'll use 1-channel version with only processed audio:
git clone https://github.com/respeaker/usb_4_mic_array.git && cd usb_4_mic_array/
pip install pyusb
python dfu.py --download 1_channel_firmware.binNow with the pacmd list-cards command, we can check if it's active. The most important here is the active profile to be set to output (analog or stereo) with multichannel input under ReSpeaker card info:
index: 2
name: <alsa_card.usb-SEEED_ReSpeaker_4_Mic_Array__UAC1.0_-00>
...
active profile: <output:analog-stereo+input:multichannel-input>
...Get in, Deep Speech.
At the time of writing this post, version 0.9.3 of Deep Speech is available in the official repository. Jetson Nano has ARM Cortex-A57 processor implementing 64-bit instruction set, which means we'll need aarch64 pre-build package. It's worth to notice that Deep Speech also provides GPU version with better performance for NVIDIA GPUs with Compute Capability greater than or equal to 3.0. According to NVIDIA documentation Jetson Nano gets the result of 5.3, but there's no pre-build gpu package for it's architecture. I think it will be worth to build such a package by myself in future to compare the results. For now I'm using CPU-based package.
First of all, I need to check the current python version. With python3 --version command it says I have 3.6.12, and the required is 3.7. Let's sort it out then with help of deadsnakes PPA:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.7 python3.7-dev
python3.7 -m pip install cythonNow I'm ready to get the latest Deep Speech wheel and install it:
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-cp37-cp37m-linux_aarch64.whl
python3.7 -m pip install deepspeech-0.9.3-cp37-cp37m-linux_aarch64.whl The next step is to prepare a model for predictions. DeepSpeech has already complete documentation for training its own model and also a pre-trained model ready to use. Training own model has some specific hardware requirements for using GPU-based deep speech. It gives more possibilities to optimize training factors and with the use of Common Voice training data - it can fits very well projects that should operate in non-English languages. Although, because of the lack of a prebuilt GPU version of deep speech for aarch64, I'll use the pre-trained model from the Mozilla team for the English language.
It is available in the DeepSpeech repository:
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.tfliteDeep Speech goes brrr...
To run this set up we need one more thing - recorded audio files. Deep Speech repository comes to the rescue once again - it already contains some audio files ready to use with deep speech.
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/audio-0.9.3.tar.gzNow we're ready to run it:
deepspeech --model deepspeech-0.9.3-models.tflite --scorer deepspeech-0.9.3-models.scorer --audio audio/2830-3980-0043.wav
deepspeech --model deepspeech-0.9.3-models.tflite --scorer deepspeech-0.9.3-models.scorer --audio audio/4507-16021-0012.wav
deepspeech --model deepspeech-0.9.3-models.tflite --scorer deepspeech-0.9.3-models.scorer --audio audio/8455-210777-0068.wavResults for these audio files are following:
-
2830-3980-0043.wav: "Experience proves this"
experience proves this Inference took 1.080s for 1.975s audio file. -
4507-16021-0012.wav: "Why should one halt on the way"
why should one halt on the way Inference took 1.460s for 2.735s audio file. -
8455-210777-0068.wav: "Your part is sufficient i said"
your part is sufficient i said Inference took 1.286s for 2.590s audio file.
To make it work with the ReSpeaker array we get ready to work before (or with any other mic), we need to add some additional python libs. And yes, the DS repository rescued us again:
git clone https://github.com/mozilla/DeepSpeech-examples
sudo apt install portaudio19-dev
python3.7 -m pip install pyaudio webrtcvad halo numpy scipyAnd run deep speech with mic support.
python3.7 ../DeepSpeech-examples/mic_vad_streaming/mic_vad_streaming.py --model deepspeech-0.9.3-models.tflite --scorer deepspeech-0.9.3-models.scorer 
I know, it's not HAL 9000 yet. Anyway, that's some starting point as some environments, like deep space requires offline solutions.
There are few things that I'd like to improve in this ASR project, i.a. add the wake-up word for command listening, add support for my native polish language and make use of NVIDIA CUDA to create my own trained model. That's the idea for one of the future posts.